
Set单列集合
HashSet
- 元素是无序的,输出的元素顺序和输入的元素顺序不一致
- 元素没有索引
- 元素不允许重复,所以最多包含一个null,重复的元素不会被添加进去
- 可以使用迭代器、增强for循环来遍历Set集合,但不能通过索引的方式遍历
Set hashSet = new HashSet();
// HashSet添加元素会返回布尔值
// 添加成功则返回true,否则为false
System.out.println(hashSet.add("java")); // true
System.out.println(hashSet.add("app")); // true
System.out.println(hashSet.add("java")); // false
System.out.println(hashSet.add("py")); // true
System.out.println(hashSet); // [app, java, py]HashSet底层其实调用的是HashMap,而 HashMap 的底层则是数组+链表+红黑树
// 单向链表
public class Set02 {
public static void main(String[] args) {
Node1[] node1 = new Node1[16];
Node1 java = new Node1("java", null);
node1[1] = java;
Node1 py = new Node1("py", null);
java.next = py;
Node1 hi = new Node1("hi", null);
py.next = hi;
// node1[1] = java
// java.next = py
// py.next = hi
System.out.println(node1[1].next.next); // hi
}
}
class Node1 {
// 存放数据
Object item;
// 指向下一个点
Node1 next;
public Node1(Object item, Node1 next) {
this.item = item;
this.next = next;
}
}// 链接关系
node[1] = java;
java.next = py;
py.next = hi;元素添加方式
视频讲解:0520_韩顺平Java_HashSet扩容机制_哔哩哔哩_bilibili
当添加一个元素时,该元素的哈希值将转换为索引值,该元素就存放在对应的索引位置(数组)
判断索引处是否有元素,有则进行equals判断,如果相同,则放弃添加,不相同则添加到最后
当索引处的链表元素超过8,且数组大小超过64,则存储方式从链表进化为红黑树
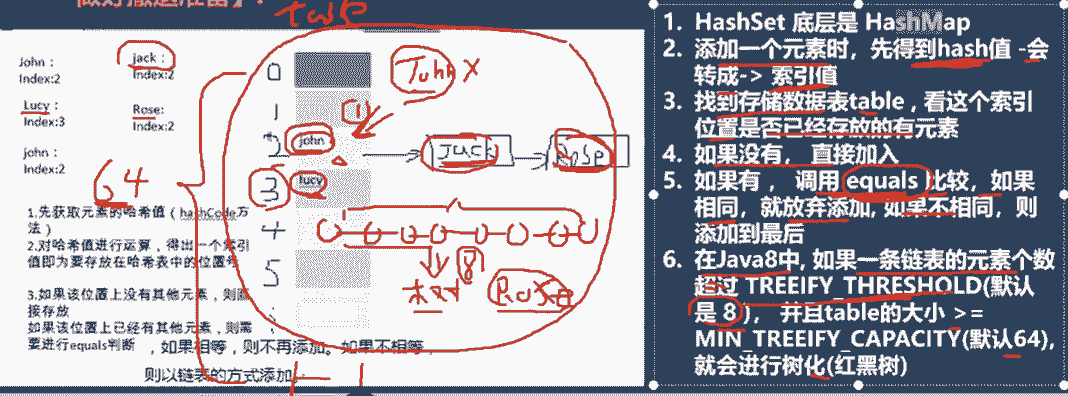
元素之间哈希值不同,则对应的索引位置也就不同
hashSet 中,两个对象的内容一样时,也会被添加
所以为了避免重复添加,修改对象中的 equals 和 hashCode 对象来实现该功能
public class Setwork01 {
public static void main(String[] args) {
Set set = new HashSet();
set.add(new Emp("zhangsan", 18));
set.add(new Emp("lisi", 20));
set.add(new Emp("wangwu", 25));
set.add(new Emp("wangwu", 25));
System.out.println(set); // [lisi 20, wangwu 25, zhangsan 18]
// 不重写 equals 和 hashCode 的话会输出两个 wangwu 25
}
}
class Emp {
String name;
int age;
public Emp(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return name + " " + age;
}
@Override
public boolean equals(Object o) {
/*
* true表示不添加
* false表示添加
* */
// 当前对象与判断对象是否为同一个对象
if (this == o) return true;
// 判断对象是否为null,判断当前对象与判断对象是否为同一个类
if (o == null || getClass() != o.getClass()) return false;
// 将判断对象转换为Emp类(自己创建的对象)
// 方便后面调用属性
Emp emp = (Emp) o;
// 当前对象的值与判断对象的值是否相等
return age == emp.age && Objects.equals(name, emp.name);
}
@Override
public int hashCode() {
// 根据多个输入值(这里是 name 和 age)计算并生成一个组合的哈希码
// 所以两个对象中只要name和age一样
// 那么这两个对象的哈希值也就一样
// 哈希值一样就不会重复添加
return Objects.hash(name, age);
}
}LinkedHashSet
- 是HashSet的子类
- 底层是
LinkedHashMap - 输入和输出的顺序是一致的
- 不能重复添加相同的值
TreeSet
TreeSet会提供一个构造器,用来自定义排序方法- 元素不允许重复
- TreeSet的底层是TreeMap
TreeSet t = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
// 比较字符串的大小
// 两个字符串的首字母比较,首字母相等则比较下一个字母
// 大于则返回正数
// 小于则返回负数
// 相等则返回 0
return ((String) o2).compareTo((String) o1);
}
});
t.add("jack");
t.add("tom");
t.add("sp");
t.add("sp");
t.add("a");
// 自定义排序前 [a, jack, sp, tom]
// 自定义排序后 [tom, sp, jack, a]
System.out.println(t);